
2024 年 6 月 2 日,輝達創辦人黃仁勳於台大體育館進行演說,雖然多數為工業應用,但輝達對於生技醫療的加速運算比例也日益增長、值得關注,基因線上特別進行重點報導。
在過去幾十年中,運算機領域發生許多巨大變革,特別是 GPU 加速運算的出現。黃仁勳在演講中深入探討塑造這一轉變的重要里程碑和技術進步,並特別強調 2006 年 NVIDIA 推出的 CUDA 技術。他分析分析 CPU 與 GPU 的性能擴展、GPU 加速系統的效率與成本效益,以及 CUDA 函式庫的多樣化應用。此外,他也分享 CUDA 創造的良性循環、深度學習模型的演變以及 AI 工廠的革命性影響。
Why NVIDIA’s CEO Huang Said AI Fostering Life Science:Highlighting GPU’s Applications in Biotech(基因線上國際網)GPU 加速運算變革性的引領人工智慧指數成長
性能擴展:CPU 與 GPU
運算性能的第一個重大轉變,是發現僅依賴 CPU 已無法滿足不斷成長的資料和運算需求。回顧過去,CPU 性能雖穩定成長,但此成長速度已被資料和運算需求的指數級上升所超越。2006 年,隨著 NVIDIA 推出的 CUDA 技術,為 GPU 加速運算帶來重大變革。這一變革充分體現在性能擴展上,相對 CPU 性能呈現緩慢的上升,GPU 性能則出現突破性的成長,反映出兩者巨大的成長差距。
GPU 加速系統的效率和成本效益
黃仁勳表示,對比僅使用 CPU 和 CPU/GPU 共同存在的 2 種配置,可以襯托出引入 GPU 的顯著優勢。與僅使用 CPU 的系統相比,GPU 加速系統可提供大約 100 倍的加速效果,然而電力消耗僅增加 3 倍,成本則僅增加 1.5 倍,突顯出 GPU 加速運算的經濟和能源效率。黃仁勳打趣的提出「買得越多,省得越多」的價值主張,強調投資 GPU 技術的價值。
CUDA 函式庫:開創新市場

黃仁勳也在演講中列舉 NVIDIA 的 CUDA 函式庫,它在擴展 GPU 加速運算應用方面發揮重要作用。主要的 CUDA 函式庫包括:
- cuDNN:深度學習
- Modulus:物理模擬 AI
- Aerial RAN:AI 無線電
- cuLITHO:運算光刻
- Parabricks:基因定序
- cuOPT:組合優化
- cuQUANTUM:量子運算模擬
- cuDF:資料處理
這些函式庫顯示出 CUDA 技術在各個科學、工業和技術領域持續推動進步,開拓新機會和應用。
CUDA 開啟開發者與市場的正向循環
黃仁勳表示,CUDA 技術創造一個自我強化的良性循環,推動持續改進和採用。這個循環從不斷成長的 CUDA 建置基礎開始,為開發生態帶來顯著性能提升,性能提升後則會吸引更多的開發人員和應用,進而吸引更多的雲端服務提供商(CSP)和原始設備製造商(OEM)參與。最後這些參與進一步擴大研究與開發(R&D)努力,帶來技術躍進,最終造福終端用戶,再度回到擴大 CUDA 的建置基礎。
深度學習模型演變:平凡誕生、偉大成長
就像每個科技巨頭演講一樣,黃仁勳娓娓道來行業發展史。
AlexNet:深度學習的突破
2012 年推出的 AlexNet 標誌著深度學習領域的關鍵時刻,被稱為「首次接觸」。這個神經網絡顯示深度學習模型在處理大量資料方面的強大能力,推動圖像識別等 AI 應用的重大進步。AlexNet 的成功強調資料在訓練深度學習模型中基礎的重要性,也為進一步創新奠定堅實的基礎。
Transformer 模型:翻轉自然語言處理的時代
2017 年推出的 Transformer 模型翻轉自然語言處理(NLP)和其他領域。這些模型展示出高效處理和轉化大量資料的能力,為 NLP 應用帶來重大進展。Transformer 對 AI 研究和應用的影響,突顯出深度學習模型的持續演變和精細化。
模型運算規模的指數級成長
AI 模型的運算規模呈現指數級成長,從 AlexNet、Transformer 模型乃至於更高級的模型。這一成長趨勢表現使運算規模在越來越短的時間間隔內翻倍,例如:AlexNet 每年翻倍、Transformer 每 6 個月翻倍,物理 AI 模型每 3 個月翻倍等,顯現當前對運算能力日益成長的需求,同時各界也積極投入先進 AI 研究和應用。
AI 工廠概念興起:推動第四次工業革命
「AI 工廠」的概念象徵著 AI 對各行各業的革命性影響,揭示由 AI 技術驅動的新工業革命。AI 工廠代表著生產 AI 模型和應用的設施,推動運算、醫療保健、交通、製造和其他行業的重大進步。AI 工廠的經濟潛力巨大,並對全球經濟成長有顯著貢獻。
全面重塑(Full Stack Reinvention):生成式 AI 的驅動
生成式 AI 正在推動技術堆疊的全面重塑,從傳統的軟體開發轉向 AI 驅動開發。這一轉變不僅囊括單一組件的改良,還包括對整個技術全面重新設計。傳統的軟體工廠仰賴 CPU 處理,現在則被依賴 GPU 處理和生成式 AI 技術(如大型語言模型)的 AI 工廠取代。這一變革正在重塑各行業,開啟 AI 開發新應用大門。
NVIDIA 的雄心壯志,建置地 2 顆地球(Earth 2)

黃仁勳表示,Earth 2 是輝達利用物理 AI 模擬出的地球環境,專為透過 AI 加強的高解析度模擬來提升氣候和天氣預測。平台利用如 DGX™ GH200、HGX™ H100 和 OVX™ 超級電腦,目標是提供快速且大規模的全球大氣模擬。主要功能包括:高解析度模擬、AI 和機器學習整合、交互式視覺化和支援氣候研究的專門工具及服務。
NVIDIA 推論微服務和 NeMo 的生成式 AI
NVIDIA 推論微服務
NVIDIA 的推論微服務架構設計用於支持高效的 AI 推論任務。這個微服務包括預訓練的模型,針對廣泛的 CUDA 安裝基礎進行優化,確保兼容與效率。架構中包含各種組件,包括 Triton 推論伺服器、雲端原生堆疊、企業管理功能和 TensorRT-LLM,所有這些都集成在 CUDA 生態系統中,此設置也促進了 AI 工作負載的無縫部署與優化。
NVIDIA NeMo:啟用生成式 AI 推論
NVIDIA NeMo 提供強大的生成式 AI 推論功能,處理各種輸入類型,如文字、圖片、影片、語音和多模態數據。該平台生成多樣的輸出,包括圖片、影片、3D 模型、聲音、動畫等。NeMo 的多功能性和強大能力在於將輸入數據轉化為有意義的輸出,突顯其在推動生成式 AI 應用中的影響力。
Hippocratic AI 生成式人工智慧數位醫療應用
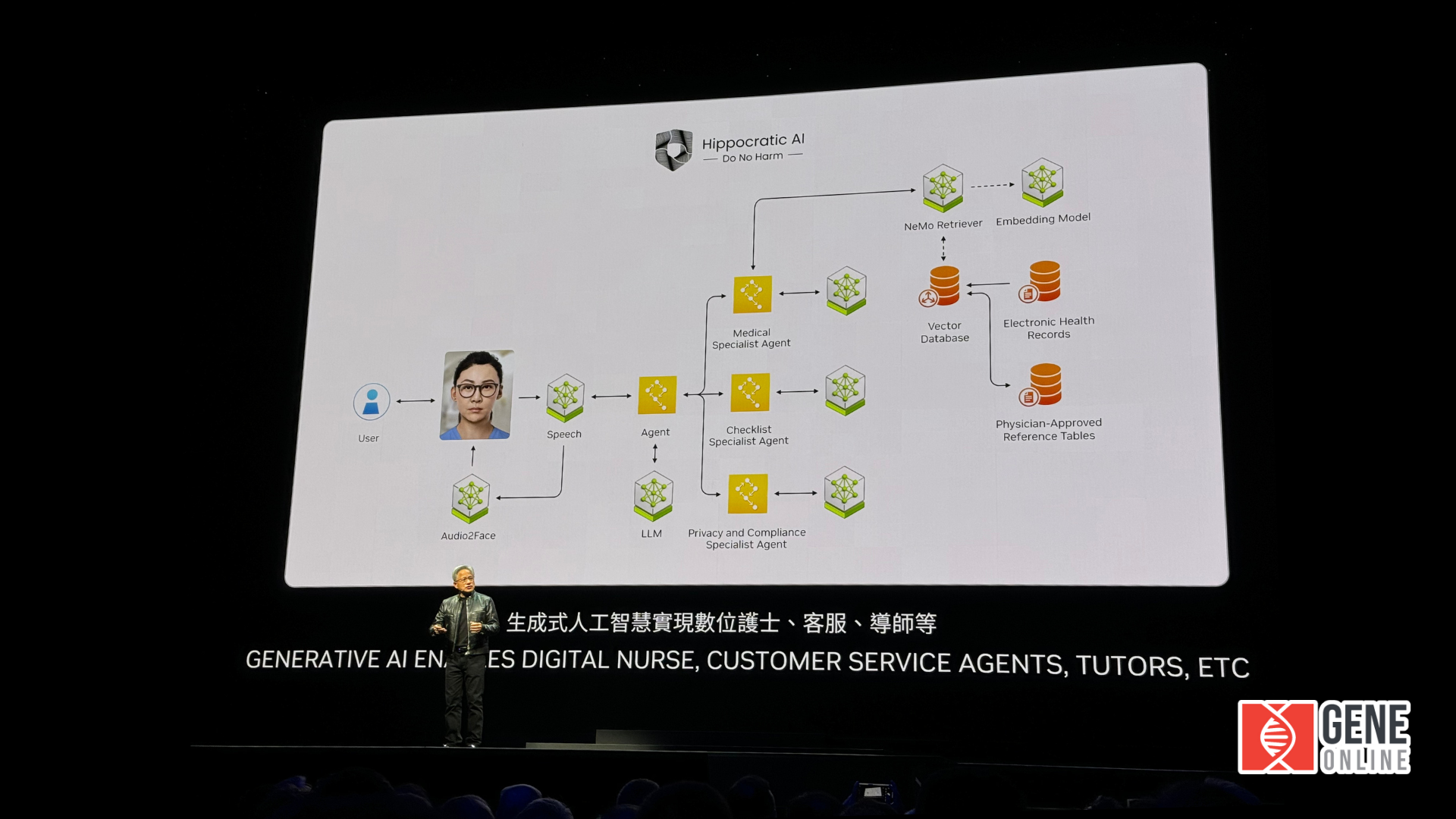
黃仁勳分享 NVIDIA 數位醫療應用「Hippocratic AI」的角色,及其與各種 AI 模型和代理的整合。使用者透過語音與系統互動,語音由 Audio2Face 模組處理,生成虛擬面孔以進行互動。接著,語音由不同的 AI 代理處理,包括醫療專家代理、清單專家代理以及隱私和合規專家代理。
Hippocratic AI 確保實踐 AI 倫理,遵循「不傷害」的宗旨。AI 代理使用各種 AI 模型和資料庫來提供準確的資訊和回應,這些模型包括 NeMo 檢索和嵌入模型、向量資料庫、電子健康記錄和經醫師批准的參考表。整個工作流程包括語音互動、AI 代理處理和資料檢索與處理,確保資訊的準確性和可靠性,顯示生成式 AI 在數位護士、客服和導師等應用中的潛力,同時也強調這些 AI 系統在提供可靠且無害的幫助時所遵循的倫理標準。
RTX AI 電腦在推動 AI 運算方面的作用
新款 RTX AI 電腦的推出代表 AI 驅動運算的一項重大進步。這些筆記型電腦配備高達 700 AI TOPS 的生成式 AI 能力,為專業和創意應用提供有力的工具。超過 200 款 RTX AI 筆記型電腦的廣泛範圍,突顯 NVIDIA 致力提供針對各行業需求的高性能運算解決方案。
NVIDIA Blackwell 平台:突破 AI 性能天花板

主要功能和組件
NVIDIA Blackwell 平台設計用於支持大規模生成式 AI 應用。主要功能包括:
- AI 超級晶片:包含 2000 億個晶體管,針對變壓器模型進行優化。
- 安全 AI:提供全性能加密和可靠執行環境(TEE)。
- 第五代 NVLink:可擴展至 576 個 GPU,提供高頻寬和連接性。
- RAS 引擎:確保 100% 的系統內自測,增強系統的可靠性。
- 解壓引擎:每秒 800 GB 的解壓縮速度。
能效的指數級成長
隨著 NVIDIA GPU 架構的進化,生成 GPT-4 詞元所需的能量顯著減少。從 2016 年的 Pascal 架構到 2024 年的 Blackwell 架構,能量消耗減少了 45,000 倍,凸顯 NVIDIA 在 GPU 技術和能效方面的進步。
DGX Blackwell 與 DGX Hopper 系統的對比
DGX Blackwell 系統相較於 DGX Hopper 系統,在多個指標上展現重大躍進:
- NVLink 域數量增加 9 倍
- NVLink 帶寬增加 18 倍
- AI FLOPS 增加 45 倍
- 功耗增加 10 倍
這些優化顯示出 DGX Blackwell 系統在運算能力、帶寬和總體效率方面的顯著提升。
NVIDIA 平台未來展望
NVLink Switch Chip
NVLink Switch Chip 的技術規格顯示高性能和先進的連接能力:
- 500 億個晶體管,使用 TSMC 的 4NP 製程技術
- 72 端口 400G SerDes,支持高速數據傳輸
- 4 個 NVLinks,每個提供 1.8TB/sec 的數據傳輸速度
- 7.2TB/sec 的全雙工頻寬,允許同時數據傳輸和接收
- SHARP In-Network Compute,提供 3.6 TFLOPS 的 FP8 性能
Spectrum-X 平台
Spectrum-X 平台設計用於增強生成式 AI 的乙太網路能力。主要組件包括:
- Spectrum-X800 乙太網路交換機:提供 1.6 倍的有效頻寬,支持生成式 AI 應用。
- BlueField-3 400G SuperNIC:提供高效的 400G 連接。
Spectrum-X 技術的年度進展
Spectrum-X 技術的年度進展呈現其擴展到數百萬個 GPU 的能力:
- 2024 – Spectrum-X800:支持數萬個 GPU
- 2025 – Spectrum-X800 Ultra:支持數十萬個 GPU
- 2026 – Spectrum-X1600:支持數百萬個 GPU
黃仁勳表示,NVIDIA 致力於增強其網路解決方案的能力,以滿足 AI 和高性能運算基礎設施日益成長的需求。
GB200 超級晶片
GB200 超級晶片包含兩個 Blackwell GPU 和一個 Grace CPU,提供平衡和高效的運算解決方案。這一配置展示 NVIDIA 最新 GPU 和 CPU 技術的強大協同作用,設計用於處理高運算任務,包括先進的 AI 應用。
一代比一代強大:Hopper、Blackwell 和 Rubin

NVIDIA 的數據中心平台呈現了 GPU、CPU、NVLink、NIC 和交換機技術的演進。每個平台的主要組件展示了技術的進步和 NVIDIA 致力於推動數據中心應用的進步。即將推出的 Rubin 平台,其高頻寬 GPU 和 Vera CPU 展現出性能的躍遷。
GPU 加速運算和 AI 大未來
黃仁勳表示,由 NVIDIA 的 CUDA 技術推動 GPU 加速運算,已經徹底改變運算領域。從提升性能和效率到開啟新應用和市場,GPU 為日益成長的數據和運算需求提供了解決方案。GPU 技術的持續創新,以 Blackwell 平台和 NVIDIA Omniverse 的整合生態系為代表,預示著 AI 和高性能運算將繼續推動技術進步的未來。
對於未來,GPU 加速運算和 AI 在推動各個領域進一步發展方面的潛力依然巨大。隨著深度學習模型、能效和綜合平台的持續發展,綜效運算的未來將變得更加變革性和具有影響力。
延伸閱讀:黃仁勳加持讓生科不科科?深度解析生命科學如何衝上 AI 浪潮之巔©www.geneonline.news. All rights reserved. 基因線上版權所有 未經授權不得轉載。合作請聯繫:service@geneonlineasia.com



